Merging INDSTAT4 data with TPP
Last update: 13 February, 2022
This section matches output series from TPP and INDSTAT4 datasets by country.
Merge Basis
- TPP data is reported in ISIC Rev 2 at the 3-digit level
- Raw INDSTAT4 data is provided in ISIC Rev 3 or ISIC Rev 4 at the 3- and 4- digit level, with some combined codes.
- The INDSTAT4 data used for matching have been coerced to 4-digit ISIC values, and then transformed into ISIC Rev 2 at the 3-digit level via 4-digit concordance.
- After conforming the country codes, TPP output data are joined with corresponding INDSTAT4 data by country.
- Note that some country series do not have a direct correspondence due to reporting differences (e.g. China/Hong Kong)
Data Preview
TPP as reported in ISIC Rev 2:
head(data_TPP, n = 100)INDSTAT4 after transformation to ISIC Rev 2:
head(data_INDSTAT$REV3, n = 100)Data Issue: Mismatching country codes
- Unfortunately TPP & INDSTAT4 datasets use different country codes.
- TPP data is reported using 3-letter ISO alpha-3 codes, though likely not the latest ISO standard as it uses “BLX” for Belgium/Luxembourg
- INDSTAT seems to use UN Statistics Division M49 3-digit numeric codes
- The World Integrated Trade Solution (WITS, World Bank, 2010) website has an Country Codes annex that seems to cover the alpha-3 codes in TPP & the UNSD numeric codes. However, there is no delimited version for download.
- Rather than using an external concordance table, we use the country code-name conversion tables provided with each dataset.
- There are three of these tables in total, one each for INDSTAT4 revisions, and one for the TPP database
Solution: Match INDSTAT4 countries to TPP countries by name
- Collapse INDSTAT4 Rev 3 & Rev 4 country tables into single lookup table:
- check for conflicts, i.e. same country code but different country names
- Merge INDSTAT & TPP tables by country name strings keeping all rows (
fulljoin).- Exact matches can be used as is.
- Examine and manual correct unmatched TPP country names:
- try to find match from INDSTAT countries, including already matched codes as some series may only match over a subset of years (i.e. different handling by TPP/INDSTAT of country splits)
- check remaining unmatched INDSTAT series to see if any should be combined with existing matches (e.g BEL/LUX)
- Manually input corrections
- create concordance table from INDSTAT to TPP (dropping INDSTAT countries without matches)
- edit TPP or INDSTAT data to create merged series where necessary
- apply concordance to edited INDSTAT
Country Code Fixes
(1) INDSTAT4 Country Inclusion
- Combine INDSTAT Rev 3 & Rev 4 tables into single lookup
- Load both tables, group by code, check for conflicting country names under a single code –> merged the two tables into one covering all country codes used in either dataset
- For Rev 3 & Rev 4, found no name conflicts, though some codes/countries only appear in one revision
## combine indstat tables
rbind_indstat <- load_rbind_INDSTAT_country_tables(here("data/external/country_codes"))
rbind_indstat## compare across revisions
compare_INDSTAT_country_tables <- function(rbind_df){
## compute comparison
missing_df <- rbind_df %>%
add_missing_flag()
## plot countries not in both tables
plot <- missing_df %>%
filter(in_all_tables == FALSE) %>%
ggplot(aes(x = source, y = name)) +
geom_point(aes(colour = source)) +
scale_color_viridis_d() +
labs(x = "revision", y = "country name",
title = "Countries with INDSTAT4 data in only ONE Revision") +
guides(colour = "none") +
theme_light()
## pivot table to show missing
compare_df <- rbind_df %>%
pivot_wider(names_from = "source", values_from = "code")
## list results
results <- list(compare_df, plot)
return(results)
}
compare_INDSTAT_country_tables(rbind_indstat) ## Test passed 🥇## [[1]]
## # A tibble: 148 × 3
## name REV3 REV4
## <chr> <chr> <chr>
## 1 Afghanistan 004 <NA>
## 2 Albania 008 008
## 3 Algeria 012 012
## 4 Angola 024 024
## 5 Argentina 032 <NA>
## 6 Armenia 051 051
## 7 Aruba 533 <NA>
## 8 Australia 036 036
## 9 Austria 040 040
## 10 Azerbaijan 031 031
## # … with 138 more rows
##
## [[2]]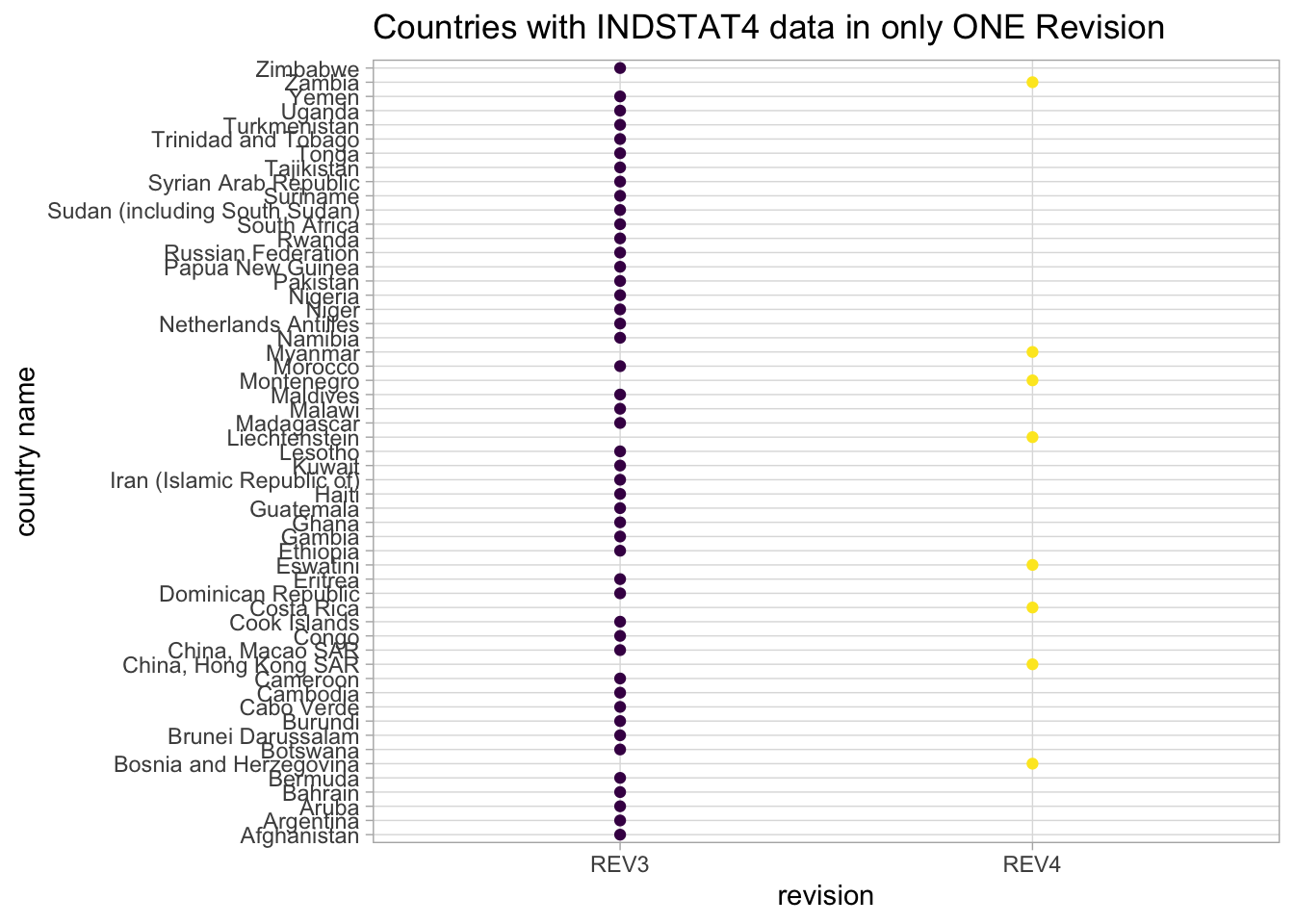
(2) Merge INDSTAT & TPP country tables
- combine INDSTAT table with TPP table by country name strings
- ignore unused country codes (i.e. codes without data)
- No point to correct country codes that are not used
- Reduces number of TPP codes without matches from 127 to ~27 (26 after removing ETH duplicate)
lookups <- list()
# combine-INDSTAT-country-lookup
lookups$indstat <-
make_INDSTAT_country_table(countryCodes_folder) %>%
conform_indstat("country") %>%
limit_to_used_codes(bind_rows(data_INDSTAT), ., code.num)## Test passed 🎊# import tpp country table
lookups$TPP <- import_TPP_country_table(countryCodes_folder) %>%
conform_TPP("country")
# make joined lookup
lookups$joined <- merge_country_lookups_by_name(lookups$TPP, lookups$indstat) %>%
limit_to_used_codes(data_TPP, ., code.alpha)
head(lookups$joined)(3) Inspect Country Code Matches
name-code duplicates
- Some country codes might be mapped to multiple other codes or names.
- Use
show_value_conflicts() - The only conflict needing correction is
code.alpha == "ETH", which lists “Ethiopia” twice.
## check joined table for conflicts & duplicate matches
map(c(expr(code.alpha), expr(code.num), expr(name)), show_value_conflicts, lookup_df = lookups$joined)## [[1]]
## # A tibble: 2 × 4
## code.alpha name code.num n
## <chr> <chr> <dbl> <int>
## 1 ETH Ethiopia 231 2
## 2 ETH *Ethiopia NA 2
##
## [[2]]
## [1] "`code.num` has no conflicts"
##
## [[3]]
## [1] "`name` has no conflicts"Country codes without matches
- draft corrections based on search & manual examination
- grouped by correction decision
- 20 TPP alpha codes without matches via name-strings
- 9 x no matching INDSTAT series; note CRI & MMR have no match in REV3
- 7 x matching INDSTAT series (string names didn’t match)
- 4 x probable/combined series matches
- Flagged series needing additional checks after plotting due to potential series mismatches
- CZE & SVK – Czech Republic/Czechia & Slovakia – separate matches but adjustments could be different in source data
- DEU – West Germany only in TPP before 1990
- BLX – Combined series
- “china” – CHN, TWN – 156 (China), 158 (China, Taiwan Province), 446 (China, Macao SAR)
# x : No matches (9)
x BEN : No match to "Benin", "Bahomey"
x CIV : No match to "Cote", "D'Ivoire", "Ivory" or "Coast"
x GAB : No match to "Gabon". Independent from France in 1960, no other names searched
x GTM : No match to "Guatemala", "guat"
x HND : No match to "Honduras"
x MOZ : No match to "Mozambique", "moz"
x SLV : No match to "Salvador", "el", "sal"
x VEN : No match to "Venezula", "ven"
x UGA : No match to "Uganda", "ugan"
# < : Mismatch in string only - e.g. name order (7)
< BOL : String mismatch with 68 (Bolivia (Plurinational State of))
< KOR : String mismatch with 410 (Republic of Korea)
< MAC : String mismatch with 446 (China, Macao SAR)
< MDA : String mismatch with 498 (Republic of Moldova)
< TWN : String mismatch with 158 (China, Taiwan Province)
< TZA : String mismatch with 834 (United Republic of Tanzania)
< USA : String mismatch with 840 (United States of America)
# << : Probable matches -- i.e. series inclusions might differ (2)
<< CZE : Probable match with 203 (Czechia)
<< DEU : Imperfect match with 276 (Germany), as DEU series is West Germany only before 1990
# ! : Matches across multiple codes -- i.e. match is across more than one series (2)
! BLX : Combine 56 (Belgium) + 442 (Luxembourg)
! HKG : Potential need to combine with CHN series, already matched to 156 (China). No suitable match from search of "Hong", "Kong", "China"## print missing indstat match
print_tpp_without_indstat(lookups$joined)## BEN-Benin
## BLX-Belgium and Luxemburg
## BOL-Bolivia
## CIV-Cote D'Ivoire
## CZE-Czech Republic
## DEU-Germany (West Germany before 1990)
## ETH-*Ethiopia
## GAB-Gabon
## GTM-Guatemala
## HKG-Hong Kong
## HND-Honduras
## KOR-Korea, Republic of
## MAC-Macau
## MDA-Moldova, Republic Of
## MOZ-Mozambique
## SLV-El Salvador
## TWN-Taiwan, Province of China
## TZA-Tanzania, United Republic of
## UGA-Uganda
## USA-United States
## VEN-Venezuela## search for indstat code
lookups$indstat %>% filter(str_detect(name.indstat, "Bolivia"))(4) Apply Manual Corrections
Edits to country lookup/concordance table
(
lookups$fixed <- lookups$joined %>%
fixes$remove_ETH_duplicate() %>%
fixes$edit_numeric_codes() %>%
fixes$add_combined_series_codes() %>%
fixes$remove_no_match()
)## Test passed 😀Edits combining separate series data
edited <- list()
## TPP
edited$TPP <-
data_TPP %>%
fixes$combine_TPP_CHN_HKG_data()## Test passed 🌈## INDSTAT
edited$INDSTAT <- map(data_INDSTAT, fixes$combine_INDSTAT_BLX_data)## Test passed 😸
## Test passed 😸
## Test passed 😀Merge TPP and INDSTAT4 using country name
- keep only data where a country match between TPP & INDSTAT exists
- match might be from INDSTAT REV3 OR REV4, or both
- use REV4 – 3-step transformation
- drop NA values arising from explicit NA rows in TPP data – i.e. country, year, ISIC2.3 without data
- drop unmatched TPP series (i.e. series without INDSTAT data)
- add context to matched dataset:
data_sourceid columncountry.matchTPP & INDSTAT alpha & numeric codes concatenated
matching <- list()
# drop unmatched TPP country series & NA rows
matching$TPP <-
right_join(x = edited$TPP,
y = lookups$fixed,
by = "code.alpha") %>%
drop_na(value.3)
# add alpha codes to INDSTAT data, dropping unmatched series
matching$INDSTAT.REV3 <-
right_join(x = edited$INDSTAT$REV3,
y = lookups$fixed,
by = "code.num") %>%
drop_na(year)
matching$INDSTAT.REV4 <-
right_join(x = edited$INDSTAT$REV4_3step,
y = lookups$fixed,
by = "code.num") %>%
drop_na(year)
# bind matching data into single dataset
matched_tpp_indstat <- bind_rows(matching, .id = "data_source") %>%
mutate(ISIC2.3 = as_factor(ISIC2.3),
country.match = paste(code.alpha, code.num, sep="-")) %>%
select(data_source, country.match, year, ISIC2.3, value.3)
# add country.match to lookup
lookups$matched <- lookups$fixed %>%
mutate(country.match = paste(code.alpha, code.num, sep="-")) %>%
select(country.match, name, code.alpha, code.num)# cache matched data
write_rds(matched_tpp_indstat, here::here("data/interim/003-matched_tpp_indstat.Rds"))
# cahce matched country name lookup
write_rds(lookups$matched, here::here("data/interim/003-matched_country_lookup.Rds"))Reference Code
Collapse TPP & INDSTAT country tables
# import TPP data from csv
read_TPP_csv <- function(TPP_csv){
read_csv(TPP_csv,
col_types = cols_only(ccode = col_character(),
year = col_double(),
isic3d_3dig = col_double(),
output = col_double())
)
}
load_TPP <- function(TPP_paths){
map(TPP_paths, read_TPP_csv) %>%
bind_rows()
}
# conform column names & types
conform_TPP <- function(df, table_type = c("data", "country")){
if (table_type == "data") {
rename(df, code.alpha = ccode, ISIC2.3 = isic3d_3dig, value.3 = output)
} else if (table_type == "country") {
rename(df, code.alpha = ccode, name.TPP = name)
} else {
print("Invalid table_type")
}
}
conform_indstat <- function(df, table_type = c("data", "country")){
round_thousands <- function(x) {
round(x/10^3, digits = 2)
}
conform_df <- if (table_type == "data") {
rename(df, code.num = country, ISIC2.3 = ISIC2.3digit) %>%
mutate(value.3 = round_thousands(value.3)) %>%
mutate_at(vars(code.num, ISIC2.3), as.numeric)
} else if (table_type == "country") {
rename(df, code.num = code, name.indstat = name) %>%
mutate(code.num = as.numeric(code.num))
} else {
print("Invalid table_type")
}
}
# import & limit lookup tables
import_TPP_country_table <- function(folder){
path <- list.files(countryCodes_folder, pattern = "TPP", full.names = TRUE)
raw <- read_tsv(path, col_types = cols())
return(raw)
}
import_INDSTAT_country_tables <- function(folder){
# get file names and paths
paths <- list.files(folder, pattern = "INDSTAT", full.names = TRUE)
# read tables
list_df <-
map(paths, read_csv, col_type = cols())
names(list_df) <- paths %>% str_extract(., "REV[3-4]")
return(list_df)
}
check_conflicting_names <- function(rbind_table){
test_that("no code has conflicting names", {
by_codes <- rbind_table %>%
group_by(code) %>%
summarise(n_names = n_distinct(name))
nrows_w_multiple_names <- nrow(filter(by_codes, n_names != 1))
expect_equal(nrows_w_multiple_names, 0)
})
return(rbind_table)
}
make_INDSTAT_country_table <- function(folder){
# import tables
table_list <- import_INDSTAT_country_tables(countryCodes_folder)
# check for conflicts
bind_rows(table_list) %>%
check_conflicting_names()
# make single table
joined_table <- table_list %>%
reduce(full_join, by = c("code", "name"))
return(joined_table)
}
limit_to_used_codes <- function(data_df, codes_df, code_col){
code_col <- enquo(code_col)
used_codes <- distinct(data_df, !!code_col) %>% pull(!!code_col)
used_lookup <- codes_df %>%
filter(!!code_col %in% used_codes)
return(used_lookup)
}
load_rbind_INDSTAT_country_tables <- function(folder){
#' @param folder containing indstat country code tables
# get file names and paths
paths <- list.files(folder, pattern = "INDSTAT", full.names = TRUE)
names(paths) <- paths %>% str_extract(., "REV[3-4]")
# read & combine data
rbind_table <-
map_dfr(paths, read_csv, col_type = cols(), .id = "source")
return(rbind_table)
}
add_missing_flag <- function(rbind_table){
check_conflicting_names(rbind_table)
df_missing <- rbind_table %>%
add_count(code) %>%
mutate(in_all_tables = case_when(n == max(n) ~ TRUE,
TRUE ~ FALSE)) %>%
arrange(in_all_tables)
return(df_missing)
}
merge_country_lookups_by_name <- function(lookup_TPP, lookup_indstat){
#' merges lookups on name string
all_countries <- full_join(x = lookup_TPP,
y = lookup_indstat,
by = c("name.TPP" = "name.indstat")) %>%
rename(name = name.TPP) %>%
arrange(code.alpha, code.num)
return(all_countries)
}Inspect Country Code Matches
show_value_conflicts <- function(lookup_df, key_col){
#' shows key with conflicting values
#' @param key_col code to check for value conflicts
code_col <- enquo(key_col)
name_conflicts_df <-
lookup_df %>%
drop_na(!!key_col) %>%
add_count(!!key_col) %>%
filter(n != 1)
if (nrow(name_conflicts_df) != 0) {
return(name_conflicts_df) }
else {
return(paste0("`", quo_name(key_col), "` has no conflicts"))
}
}
print_tpp_without_indstat <- function(lookup_df){
#' print TPP countries without INDSTAT matching series
lookup_df %>%
filter(is.na(code.num)) %>%
mutate(alpha_w_name = paste(code.alpha, name, sep = "-")) %>%
pull(alpha_w_name) %>%
cat(sep="\n")
}
search_name_column <- function(lookup_df, pattern){
#' shows INDSTAT results in context of partial TPP name matches
lookup_df %>%
filter(str_detect(name, regex(pattern, ignore_case = TRUE)))
}